


引言:各平台618购物节已经结束有几天了,“54321,上链接!”在热闹的直播间“买(qiang)买(qiang)买(qiang)”是参与618的一种仪式感。

6月初,巨量算数&算数电商研究院推出了全新研究IP【趋势雷达】。作为趋势雷达研究IP之「行业趋势」的第一篇,本篇美妆种草看点从新热点、新成分、新品类等角度呈现美妆行业近来的市场变化,帮助美妆行业从业者及时洞察行业风向,紧跟行业热点,研发新品,打造爆品!
同时,本期报告引入巨量算数&算数电商研究院新推出的种草工具--行业热点探测模型「火种」,帮助商家实现科学高效追热点!文末可扫取二维码加入商家VIP内测群。
一、618节点营销对美妆市场规模的拉动作用显著
618作为“错过等半年”的重磅购物节,再加上大众被压抑已久的购物欲集中释放,扫货囤货无疑正成为人们如今社交的重要谈资。
显然,美妆护肤产品几乎是所有年轻女性购物车中的必备品,毕竟变美是女生的刚需且追求永无止境。同时在近年来,使用男性护理产品也正成为年轻男士们的新兴潮流,“男颜经济”似乎也在快速崛起。
总体来看,美妆产品始终是线上电商销售的重要组成部分,而购物节的线上销量也对整个美妆市场有着举足轻重的影响。根据国家统计局数据显示,2021年全年中国化妆品类零售额累计值达到4026亿元,同比增长18.4%。其中,618所在的6月和双十一所在的11月为全年零售额最高的两个月,合计占比23.6%,两大电商节引爆了全年美妆产品的消费活力。
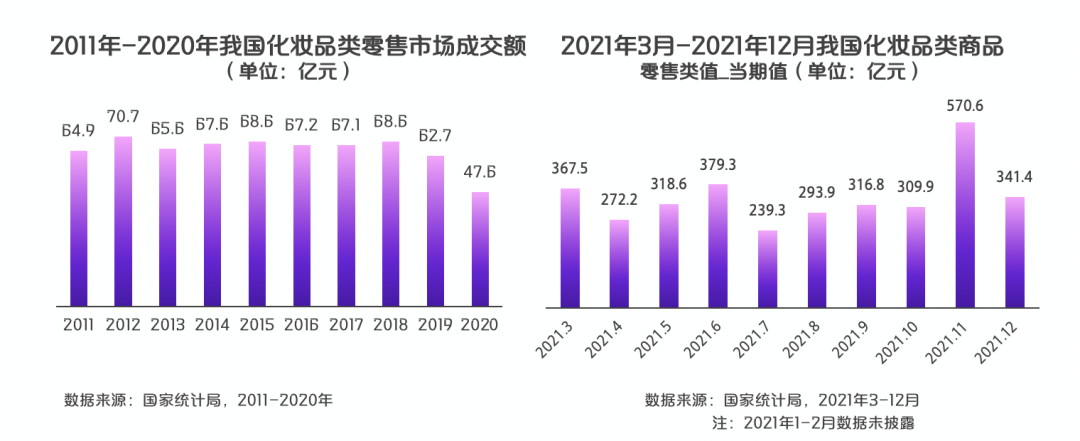
不得不说,随着物质生活的丰富,年轻人对美妆产品的选择更加多元化、个性化,这也导致近年来大量新兴美妆消费趋势的不断涌现。而抖音这类短视频内容平台,正好给予了年轻人美妆兴趣内容更为直观的展示场域,这也导致越来越多的新兴美妆消费趋势,集中在短视频平台爆发,短视频兴趣电商也便成为年轻人和品牌商家们的重要互动桥梁。
二、当消费者在兴趣内容中完成了美妆种草和拔草
在过去,人们往往通过图文页面来认知产品详情,但由于产品详情页很容易产生过度美化、过度修饰的情况,这就导致消费者对产品展示的信任度会大打折扣。很多人看到模特图片、展示图片后冲动下单,但是收到货后可能才发现“买家秀”与“卖家秀”差异之大,对于服装、美妆这类视觉审美类产品尤其如此。
同样,在过去电商平台与内容平台的割裂,让用户在消费体验上并不连贯。例如,不少女生有学习美妆技巧的需求,也会在各大平台上关注不少美妆博主/KOL,但美妆技巧内容与美妆产品下单往往并不连贯,用户在看到某美妆教程使用的产品后,并不能够无缝进行下单,这也导致用户体验上的粗糙。
但近年来短视频、直播电商平台的出现,已经较好地解决了这些用户难题。视频展示与实时直播互动,能够让美妆产品的“上脸效果”更加直观、更具展示性,同时也更能够建立消费者与产品之间的信任感。此外,视频直播内容也可以将美妆内容与美妆产品深度绑定,为消费者提供一站式购物场景。
优秀美妆种草短视频案例
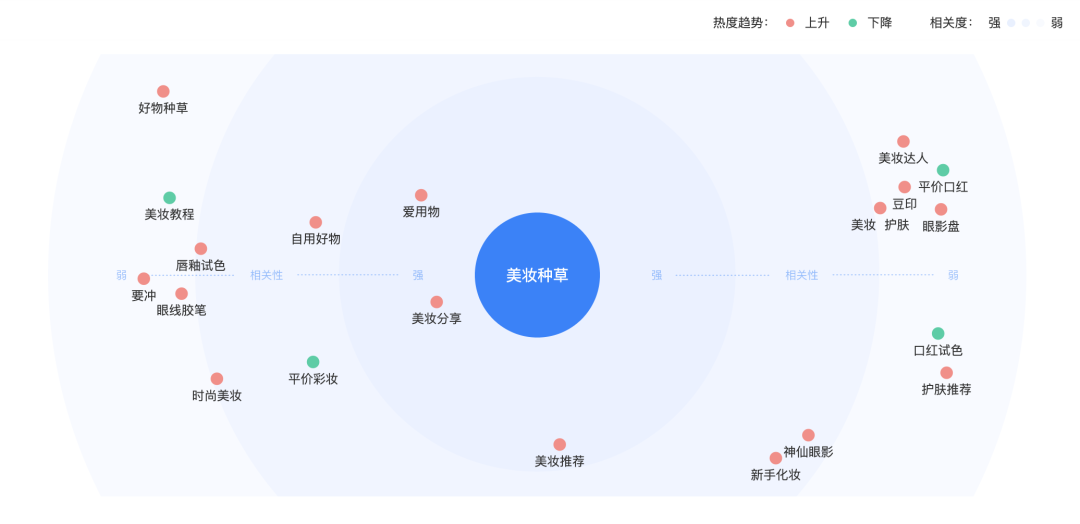
不难发现,年轻人们在短视频平台能够更高效地找到个性化的兴趣内容、兴趣作者和兴趣产品,在兴趣电商中的种草拔草、相互推荐,已经成为新一代重要的娱乐和社交方式,兴趣电商也成为美妆品牌未来发展的重要机遇。在巨量算数官网的算数指数热词关联词查询中输入“美妆种草”可发现,美妆分享、爱用物、美妆推荐、平价彩妆这类短视频内容以消费者需求为导向,从博主的实际使用心得出发,很容易赢得消费者的信赖,种草热度很高。
2022年6月“美妆种草”内容关联词热度趋势
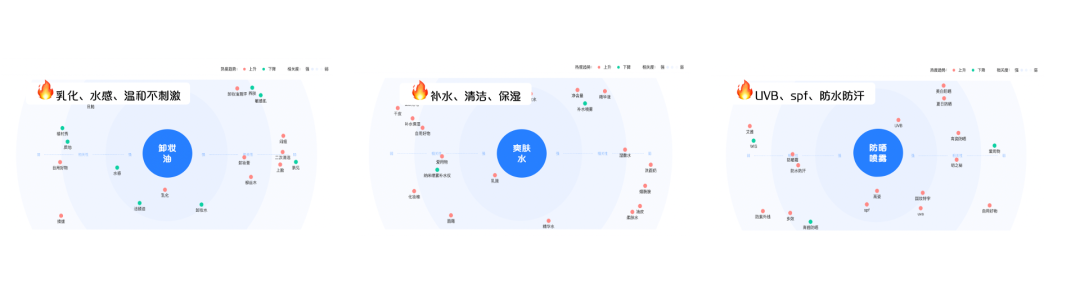
商家也可在巨量算数官网中使用算数指数产品挖掘与美妆商品有关的热度词,分析热词相关联的词云网络,通过词云筛选从消费者关心的美妆品类热点、需求的痛点和购买的买点出发,做好美妆货品卖点营销。
2022年6月美妆行业夏日趋势品类关联词热度趋势
在抖音平台上,#美妆 话题播放量达1097.2亿次,吸引了国内外品牌和美妆达人的深度参与,抖音也成为美妆行业趋势的“造风者”。
例如在抖音热点美妆话题中,#大娘级护肤金字塔 话题创建于2021年11月,在达人骆王宇的推动下,截至2022年4月,播放量便突破1.0亿次;再如2021年上半年,#沉浸式化妆 话题在抖音中新奇,吸引了蔡文玉、小来爱耍赖、微辣阿弯等众多美妆达人参与,话题播放量累计超过89.5亿次;
另外还有美妆达人与萃乐活、蒂可丽等美妆品牌共同推动的#早c晚a、#以油养肤、#精简护肤等流行话题,最终均达到数亿次级别的播放量,其中,#精简护肤 话题相关视频播放量同比增长63倍。

可以发现,由于大量年轻人的聚集,抖音电商平台的美妆种草内容趋势也更加匹配新兴生活方式,这让大量新锐美妆品牌在抖音电商中快速获得了更多关注,例如主打“稀选松茸成分”的稀物集、主打“双重真A醇”技术创新的HBN、主打“4代冻凌玻尿酸”的凌博士。
三、种草工具助力带你科学追美妆热点
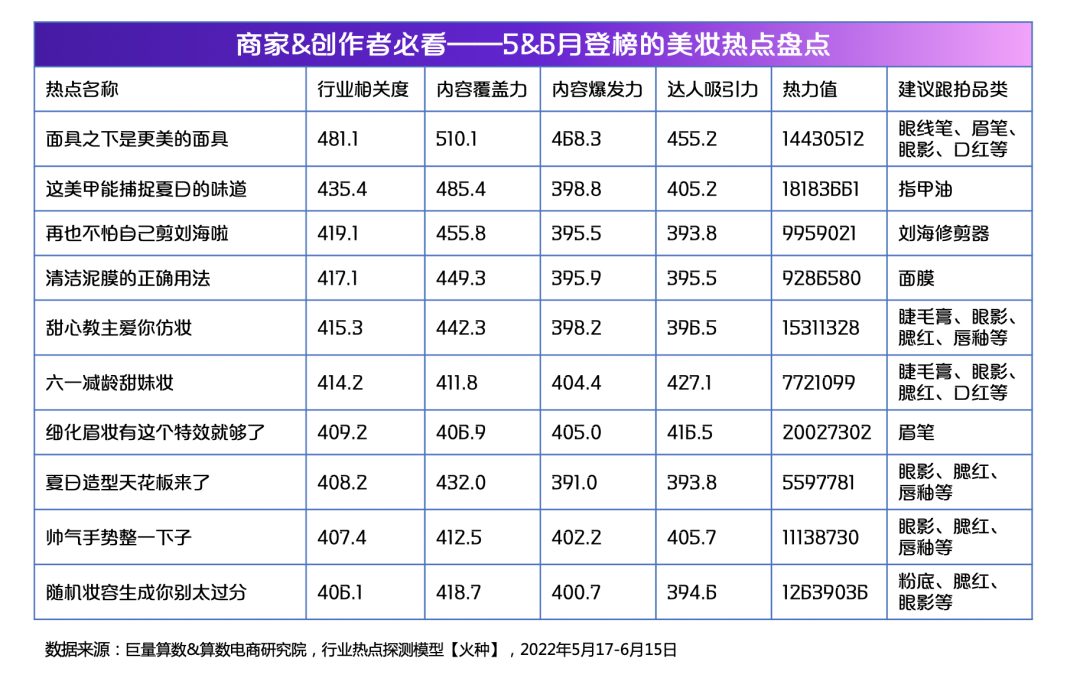
六月,算数电商研究院推出行业热点探测模型【火种】,可以帮助美妆行业内容创作者筛选抖音平台热点的指数工具。通过本工具,你可以筛选出美妆行业每日最IN、最热、关联度最高的热点话题。选择高关联、高热度热点进行跟拍,帮助“蹭”到抖音优质流量,帮你科学上热点!
以2022年5月和6月热点为例,商家可以从不同方向发掘适配热点。带有季节关键词的热点——“夏日”反映当下趋势,带有品类关键词的热点——“眉妆”和品类商家关联性强,带有节日关键词的热点——“六一”与节日关联,商家可根据推荐方向跟拍热点。
四、这届年轻人偏爱怎样的美妆品牌
当标准化产品成为日常消费的基础后,多元化、个性化显然将是消费者下一步追求的目标。越来越多年轻人乐于通过品牌来展示自身的审美与个性,而美妆产品天然就具有社交货币的属性,更是成为年轻用户展示自我的手段。
大众款解决的是60-80分的问题,而个性款、新潮款解决的是80-100分的问题,传统美妆企业通常更聚焦于消费者需求的“最大公约数”与生产供给的“规模化效应”,反而是新锐美妆品牌,补足了个性化需求的商业一环,这也让年轻人对新锐美妆品牌有着极大热情。
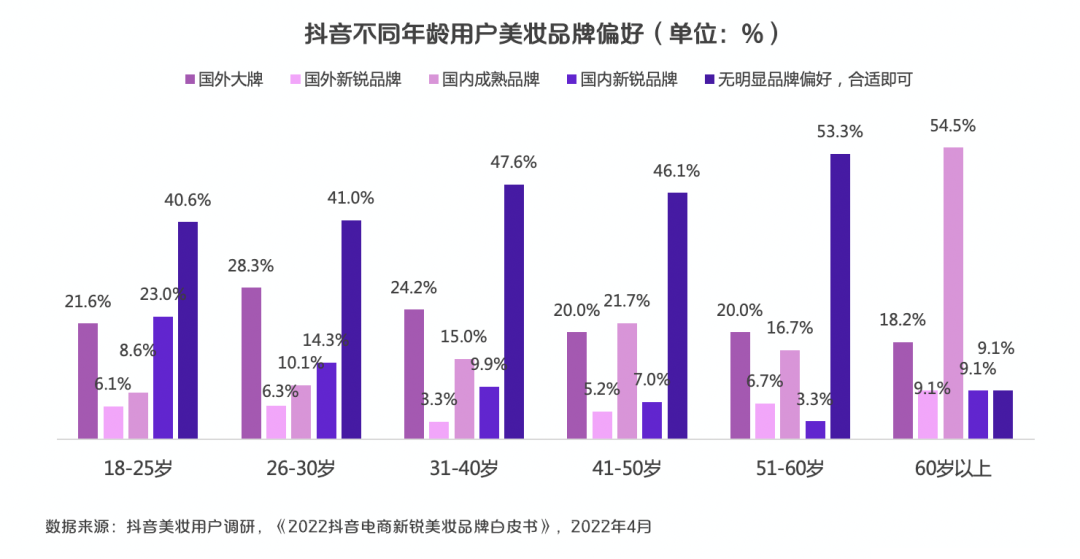
根据《2022抖音电商新锐美妆品牌白皮书》(以下简称报告)的调研数据,在抖音的美妆兴趣用户中,超过30%用户更加倾向于新锐品牌。同时,年轻用户对新锐品牌接受度更高,18-25岁年轻用户对国内新锐 品牌接受度最高,远高于国外新锐品牌。
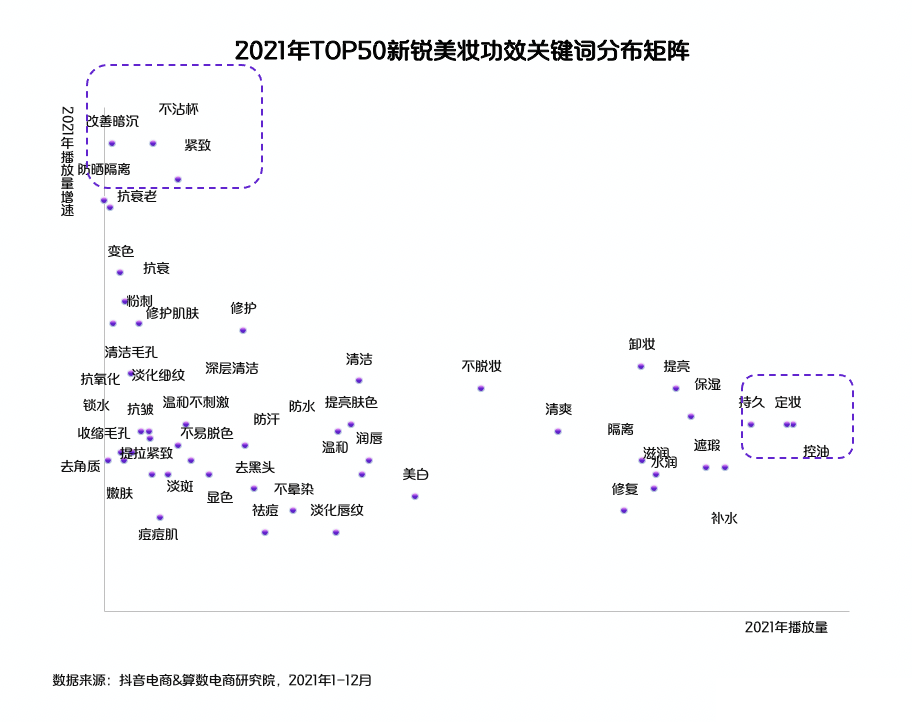
年轻消费者兴趣分层与自我意识的觉醒,让美妆产品出现了明显的个性化发展趋势,例如近年来成分党的快速崛起,就意味着用户开始追求更加具有针对性、更加定制化的护肤产品,根据自身的肌肤条件,来选取含有相应功效成分的美妆产品。
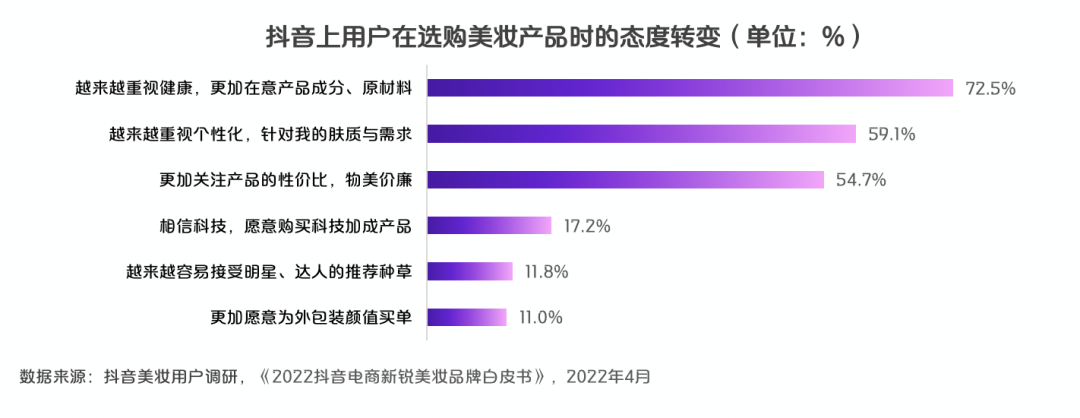
根据《报告》调研数据,72.5%的抖音美妆用户更加注重成分、原材料,59.1%的抖音美妆用户越来越重视个性化需求。另外,各个美妆品类在基础功效上都陆续添加其他成分,逐步丰富产品功能,例如保湿功能已经渗入唇釉、隔离等品类中。
同时,过去通常遭到商家忽视的小众美妆品类,如今也因个性化消费的崛起而快速增长,也就是说,垂直美妆产品正在爆发大量的市场机遇。根据《报告》的分析,美妆主流品类的内容化布局已成熟,热门的细分机会品类则是2021年新锐美妆品牌有亮点的发展方向,也代表新锐美妆未来的品类布局走势。
五、聪明的美妆品牌都在做什么在过去,传统品牌营销更多是自上而下的宣传推广,品牌商家定下广告内容与策略,然后一步步地将产品“推”到消费者面前,无论是产品还是品牌内容,消费者都只能被动地接受,然后做出选择。
但如今,聪明的美妆品牌懂得与年轻用户产生更多互动,让用户不再是被动地接受品牌信息,而是拥有足够的互动参与感。在这种品牌的游戏化养成互动中,用户会主动将产品“拉”到自身面前并分享给他人。
用户的互动与认可,正在成为美妆品牌从所在赛道中脱颖而出的关键,也是过去一年中表现优异的新锐美妆品牌最大共同点。在《2022抖音电商新锐美妆品牌白皮书》中对此有着详细的梳理分析与方法论总结,总体来说,赛道突围有三大方式:
第一是通过定制来实现差异化破圈。品牌商家可以基于消费者需求进行定制化创新,打造高效解决肌肤问题的产品,此外,品牌商家还能够通过以定制化内容和直播间深度挖掘并引导用户购买,打造品牌独有记忆点。
第二是突出健康与个性化标签。随着美妆行业消费成熟度提升,健康与个性化需求将会不断释放,从具体购买场景来看,爆款推荐、包装颜值等传统热点词汇逐渐降温,健康、个性化已经成为新热点词汇。
第三是通过礼盒的方式实现品效合一。对于消费者而言,礼盒的包装设计可以营造氛围感和仪式感,带来情绪上的满足。而对于品牌商家来说,礼盒一方面可以满足美妆产品的节点性和送礼属性,满足用户差异化需求;另一方面也可以将明星单品进行组合,用爆款带动关联产品销量增长;除此之外,联名礼盒也可以多维度拓展品牌力,实现人群快速破圈,提升品牌渗透率。
如今618活动刚刚结束,这也是一年中人们扫货美妆产品的重要时间。所谓爱美之心人皆有之,美妆产品不仅只是生活的调色剂,也成为人们表达自我、展示自我的方式。随着大量新锐美妆品牌在兴趣电商生态中不断成长、发展,中国美妆行业也将迎来百花齐放的新周期,人们对美的理解也将变得越来越多元,越来越丰富。
行业热点探测模型【火种】,现已正式面向抖音上美妆、服饰、母婴、日化行业所有品牌和商家开放内测,我们为所有内测品牌提供平台热点推荐权益,感兴趣的商家请联系“巨量算数”公众号后台,与巨量算数共同探索热点的价值。