什么是单变量分析?

单变量其实就是我们通常接触到的数据集中的一列数据。
单变量分析是数据分析中最简单的形式,其中被分析的数据只包含一个变量。因为它是一个单一的变量,它不处理原因或关系
单变量分析的主要目的是描述数据并找出其中存在的模式,也就是“用最简单的概括形式反映出大量数据资料所容纳的基本信息”。
本节我们研究的是连续数值型数据的分布。
那么什么样的数据是连续数值型数据呢?什么样的数据是离散型数据呢?
连续型数据一般应用在计算机领域,在数据挖掘、数据分类时会遇到此类数据,因其数据不是单独的整十整百的数字,包含若干位小数且取值密集,故称为连续型数据,例如,身高、体重、年龄等都是连续变量。 * 由记录不同类别个体的数目所得到的数据,称为离散型数据。例如,某一类别动物的头数,具有某一特征的种子粒数,血液中不同的细胞数目等。所有这些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度
我们要如何使用seaborn绘制单变量分布呢?
首先,使用Numpy模块从标准整体分布中随机抽取1000个数,作为我们的连续数值型数据
random是Numpy中一个随机模块,在random模块中的normal方法表示从正态分布中随机产生size数值
size=1000,表示随机产生1000个数,它们组成的数据是一组连续型的数值型数据。
在seabonr中,最常用额观察单变量分布的行数distplot(),默认地,这个函数会绘制一个直方图,丙拟合一个核密度估计。
sns.displot()的使用方法如下:
- data记录绘图所用的数据
- bins在绘制直方图时,用于设置分组的个数,默认值时,会根据数据的情况自动分为n个组,若是想要指定分组的个数,可以设置该参数,然后我们也可以增加其数量,来看到更为详细的信息
- hist和kde参数用于调节是否显示直方图和核密度估计图,默认hist、kde均True

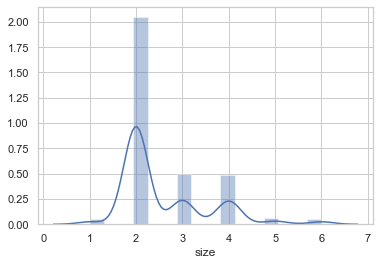
在上面的结果中,横轴表示数据点的取值,纵轴表示概率密度值。使用直方图描述了数据的分布:将数据分成若干个组,用柱形的高度记录每组中数据所占比率。
在这个图中大家还会发现比我们之前学习的柱状图多一个曲线。
这条曲线叫做概率密度曲线。就是采用平滑的峰值函数来拟合观察到的数据点,从而对真实的概率分布进行模拟。
从上图中可以看出,在数字0周围,概率密度值是最大的,但是,随着向两侧的逐渐扩展,概率密度逐渐减小。这样的分布也是一个标准正态分布。
概率密度曲线的原理比较简单,在我们知道某一事物的概率分布的情况下,如果某一个数在观察中出现了,我们可以认为这个数的概率密度很大,和这个数比较近的数的概率密度也会比较大,而那些离这个数远的数的概率密度会比较小。
如果我们只想要显示概率密度曲线,不想显示柱状图,我们也可以使用sns.kdeplot()函数绘制数据的概率密度曲线图。
- shade参数用于设置图形下方的部分是否设置影响,默认值为False,表示不绘制阴影。

以上就是连续数值型单变量数据常见的可视化方法,我们常会使用到直方图、核密度图来描述数据的分布。
在Seaborn中也集成了这两种图像,使用sns.distplot()函数可以将它们绘制在同一张图中。
有时我们不仅需要查看单个变量的分布,同时也需要查看变量之间的联系,往往还需要进行预测等。这时就需要用到双变量联合分布了。
在Seaborn中绘制连续数值型双变量我们使用sns.jointplot():
- x,y:分别记录x轴与y轴的数据名称
- data:数据集,data的数据类型为Dataframe
- kind:用于设置图形的类型,可选的类型有:scatter、reg、resid、kde、hex,分别表示散点图、回归图、残差图、核密度图和蜂巢图
如果我们希望看一看数据中两个变量在二维平面上之间的关系时,则可以使用散点图,因为散点图可以帮助我们很容易地发现一些数据的分布规律。
现在我们同样使用np.random.normal()函数创建一个含有两列数据的Dataframe,然后根据该数据绘制双变量散点图。
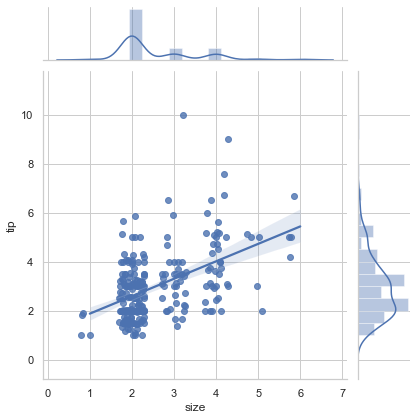
根据结果我们发现,sns.jointplot()函数可以显示两个变量之间的联合关系以及每个单变量的分布。
我们把函数中的kind参数设置为’reg’就可以做一些简单的线性模型拟合。
并且在坐标系的上方和左侧分别绘制了两个变量的直方图和核密度图。
上面我们根据数据绘制了联合散点图,但是你会发现两个数据并没有明确的线性关系,并且散点图有一个问题,就是相同的点会覆盖在一起,导致我们看不出来浓密和稀疏。
以我们可以使用蜂巢图查看一下数据的分布情况。
蜂巢图的绘制还是使用seaborn.jointplot()函数,只是将kind参数更该为hex即可。
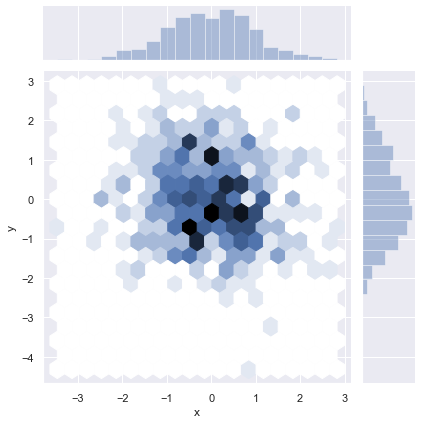
蜂巢图中每个六边形表示一个范围,用颜色表示这个范围内的数据量,颜色越白的地方数据量越小,颜色越深的地方表示数据量越大。
当数据比较大的时候使用该种方式,更容易找出数据的分布情况。
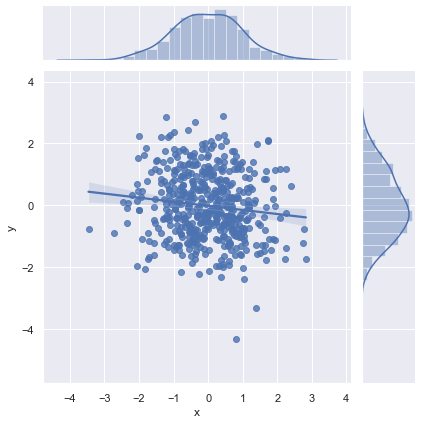
在单变量分析的时候,我们绘制了单变量的概率密度曲线,在双变量中我们也可以使用密度图来分析数据的分布情况。
密度图的绘制还是使用seaborn.jointplot()函数,只是将kind参数更该为kde即可。
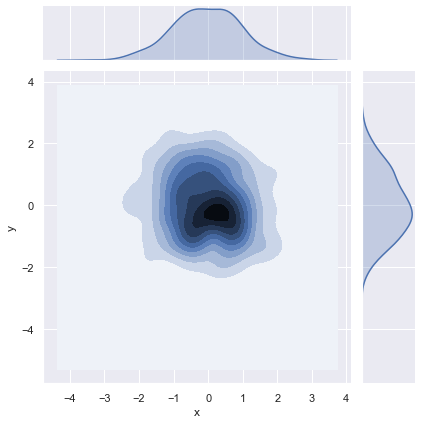
根据图形可以看出,双变量密度图是使用一些封闭但是不规则的曲线来表示,数据密度越高的地方颜色越深,数据密度越低的地方颜色越浅。
我们在做数据分析时面对的数据集中往往有很多列数据,在我们还没有确定针对哪两个变量进行挖掘的时候,比较稳妥的做法就是将数据中的每两列都考虑一次,做一个完整的变量关系可视化。
以著名的iris数据集为例,iris数据集有4个特征,那么每两个特征都考虑一次,就有16种组合。
| sepal_length | sepal_width | petal_length | petal_width | species ---|---|---|---|---|--- 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa
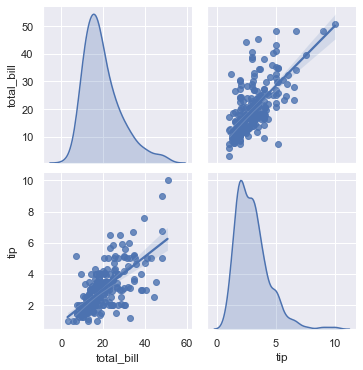
我们使用seaborn中的pairplot()方法,就可以绘制连续数值型多变量关系分布图。
参数介绍:
- data:表示绘图所用到的数据集
- hue:表示按照某个字段进行分类
- vars:可以用于筛选绘制图形的变量,用列表的形式传入列名称
- kind:用于设置变量间图形的类型,可以选择“scatter散点图”或“reg回归图”
- diag_kind:用于设置对角线上的图形类型,可以选择“hist直方图”或“kde核密度图”
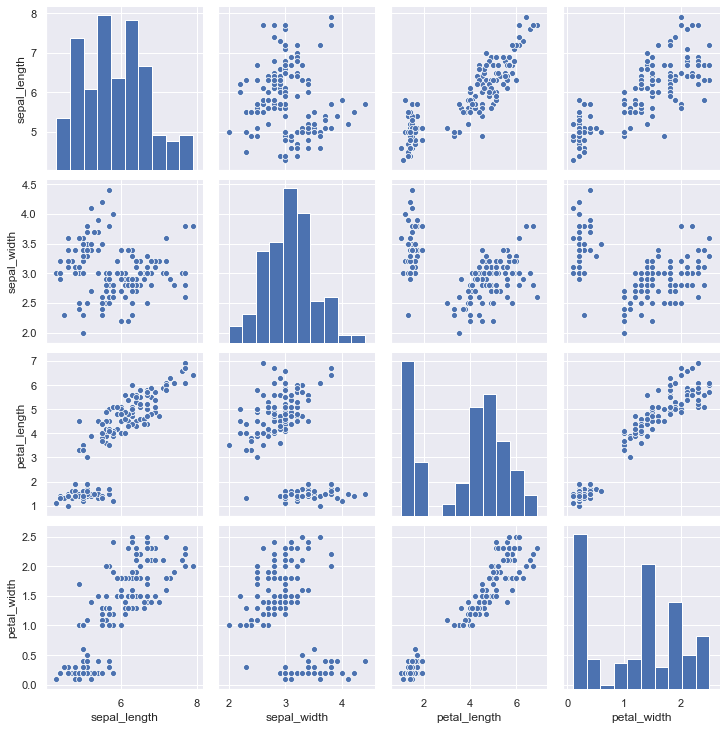
从图中可以看出,在petal_length和petal_width散点图中,呈现了比较明显的线性关系。
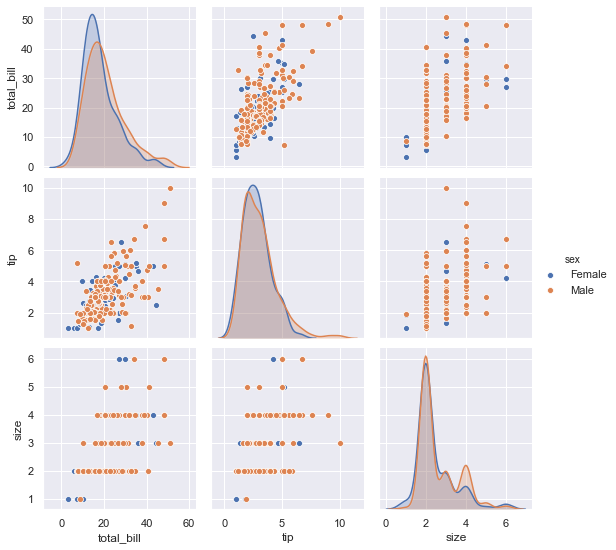
接下来我们将分类变量species考虑在图中,看看不同类别的鸢尾花的数据有没有明显的差别,将hue参数设置为species。
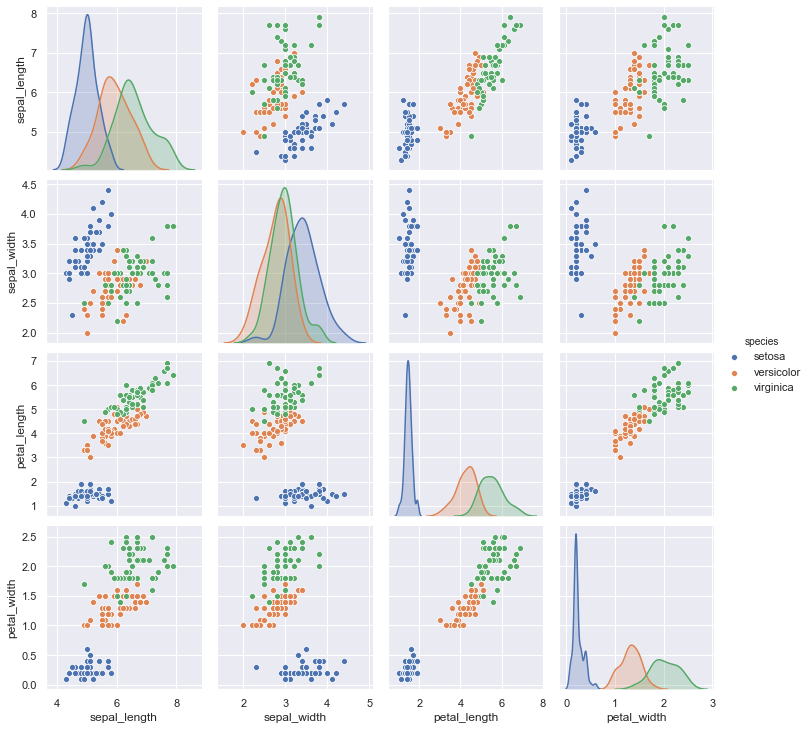
从图中可以看出,不同的颜色代表着花的不同种类,同一种的数据聚集在一起,并且与其他类别的数据交集比较少,表示三种花有明显的差别。
我们也可以使用pairplot函数绘制两个变量的关系分布图。 使用kind参数设置两个变量间使用回归图,使用diag_kind参数设置对角线上的图像类型为密度图。

我们可以根据自己对于数据的理解,设置不同的图像样式,来继续发掘数据中的信息。



- 使用数据完成以下要求:完成下面的要求: 1. 绘制出每两列变量之间的关系; 2. 不同性别的消费数据有没有明显的差别。 3. 绘制消费总额与小费两个变量的关系分布图。
| total_bill | tip | sex | smoker | day | time | size ---|---|---|---|---|---|---|--- 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4
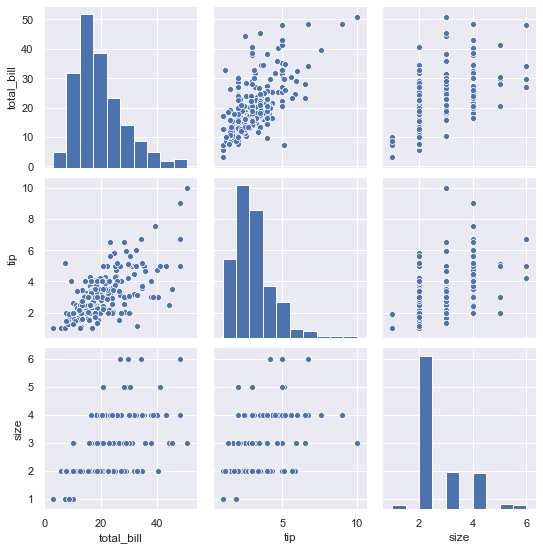
- 继续使用以上数据,完成以下要求: 1. 绘制出用餐人数的概率分布图; 2. 绘制出用餐人数与小费的散点图;
| total_bill | tip | sex | smoker | day | time | size ---|---|---|---|---|---|---|--- 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4